Local Host Cache has been introduced to FMA with XenApp & XenDesktop 7.12+ and is the recommended component to combat database outages allowing users to connect to their resources when the database is out of reach. Connection Leasing is still around and will still be enabled in many scenarios as I will discuss later.If you want to read up on Connection Leasing see https://jgspiers.com/citrix-connection-leasing/
Note: Connection Leasing has been deprecated in XenApp and XenDesktop 7.12. The feature is not removed, and will still be supported up until the next Current Release after LTSR 7.15.
From XA/XD 7.12 onwards, Local Host Cache will be the recommended feature of your Citrix farm that allows users to be brokered on to applications and desktops (pooled VDI desktops not supported, just like Connection Leasing) in the event the site database goes offline. LHC is only there to ensure contingency in that operations continue whilst you recover the database connection. So do not treat the priority of restoring a SQL connection any different than before. If you install or upgrade to XenApp/XenDesktop 7.12 all Delivery Controllers receive a LocalDB SQL Express database which stores the Local Host Cache configuration regardless of whether you use Local Host Cache or not. However if you have LHC disabled configuration synchronization using the Citrix Config Synchronizer Service does not occur.
However if you have LHC disabled configuration synchronization using the Citrix Config Synchronizer Service does not occur.
System Requirements:
- Up to 1.2GB RAM for the local database service.
- No set CPU rule but Local Host Cache will perform better with more CPU resource. The LocalDB can use up to 4 cores, but is limited to a single socket.
- Note: Assign a single socket and uo to 4 cores to your Delivery Controller virtual machines.
- Storage must be available for the LocalDB to grow during a database outage. Once the database is back online the LocalDB will shrink after it is recreated.
The way Local Host Cache works is similar to the XenApp 6.x days but with some extra improvements. When VDA’s register they register against a Citrix Broker Service running on all Delivery Controller’s in a farm. When users are brokered on to VDA’s the Citrix Broker Service is used to find a suitable machine to host the session. All the data generated from such activites including brokering information etc. is stored in the Site database.
Every 2 minutes the Citrix Broker Service on a Delivery Controller checks to see if any changes have been made to the principal broker’s configuration. Changes can include assigning desktops to users, or deleting/adding a Machine Catalog or Delivery Group. If a change has been made since the last check the principal broker uses the Citrix Config Synchronizer Service to copy the all broker configuration including new changes (which prompts a database recreation) to a secondary broker service called the Citrix High Availability Service on the Delivery Controller. The secondary broker service imports the configuration data in to a local SQL express database running on the controller. The Citrix Config Synchronizer Service then makes sure the local database matches the information in the site database.![]()
If site database access to the principal broker service (Citrix Broker Service) is lost, VDA’s re-register with the Citrix High Availability Service running on the elected controller as the Citrix Broker Service stops listening for requests and passes that job to the Citrix High Availability Service. Now any brokering communication between StoreFront and the Delivery Controller or VDA registrations involve the Citrix High Availability Service on the elected broker, which is the Delivery Controller whose name comes first in alphabetical order. As an outage occurs, only one controller is elected as the “in-charge” controller that handles all VDA registration requests and brokering duties. All Delivery Controllers in a farm use an FQDN list of each controllers name alphabetically to determine the elected broker upon database outage. If an elected controller was to fail, another available controller will take over. As only one controller is elected, it must be able to handle the additional load of VDA and brokering operations.
Also note whilst database outages are on-going, machines are not power managed, you cannot use Citrix Studio to perform administrative tasks etc. when the Local Host Cache is in use. If a user tries to broker on to a powered off VDA, you must manually power it on before that user can connect.
Once the database comes back online the Citrix Broker Service takes back the role of primary and all communication is re-routed away from the Citrix High Availability Service.![]()
Now I mentioned before that Connection Leasing is still around and enabled under many scenarios. These scenarios are:
- Installing a fresh XenApp/XenDesktop 7.12 farm results in LHC being disabled and Connection Leasing being enabled.
- Installing a fresh XenApp/XenDesktop 7.15 farm results in LHC being enabled and Connection Leasing being disabled.
- Upgrading from a farm that had Connection Leasing enabled results in CL still being enabled and LHC being disabled under 7.12+ when you have less than 5K VDA’s.
- Upgrading from a farm that had Connection Leasing disabled results in CL still being disabled and LHC being enabled under 7.12+ when you have less than 5K VDA’s.
- Upgrading from a farm that had Connection Leasing disabled or enabled results in CL still being disabled or enabled and LHC being disabled under both scenarios when you have more than 5K VDA’s.
To see if Local Host Cache is enabled simply run Get-BrokerSite on one of your Delivery Controller’s.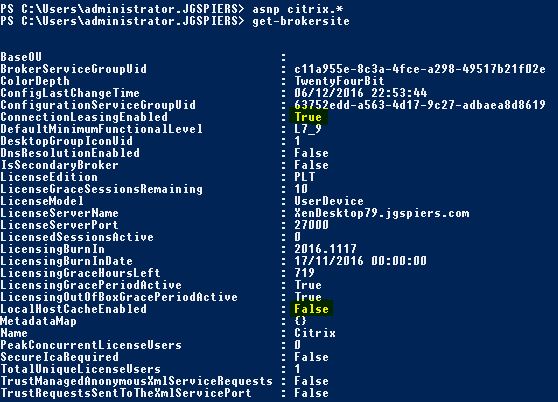
To enable Local Host Cache run command Set-BrokerSite -ConnectionLeasingEnabled $false
Now run Set-BrokerSite -LocalHostCacheEnabled $true![]()
Shortly after an event should be logged within Event Viewer stating that the Citrix Config Synchronizer Service received an updated configuration. Any time a configuration change is made within Studio or PowerShell this event will be logged. 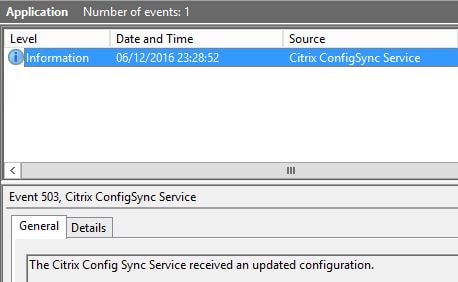 Controllers are elected based on alphabetical order. Notice how the Controller1 broker server is elected. Election takes place whilst the Site database is active.
Controllers are elected based on alphabetical order. Notice how the Controller1 broker server is elected. Election takes place whilst the Site database is active.  If Site database access is lost the Citrix Broker Service on each controller logs an event.
If Site database access is lost the Citrix Broker Service on each controller logs an event. 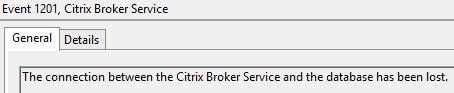 After around 1 minute the Citrix Broker Service hands operations over to the Citrix High Availability Service and we are now operating in Local Host Cache mode.
After around 1 minute the Citrix Broker Service hands operations over to the Citrix High Availability Service and we are now operating in Local Host Cache mode. 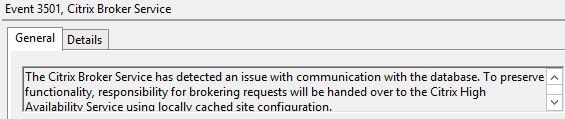 The Citrix Availability Serrvice reports it has become active and will broker user requests until the SQL database is back online.
The Citrix Availability Serrvice reports it has become active and will broker user requests until the SQL database is back online.  On your VDA’s, the Citrix Desktop Service will report it has lost contact with the non-elected Delivery Controllers and attempt to restart.
On your VDA’s, the Citrix Desktop Service will report it has lost contact with the non-elected Delivery Controllers and attempt to restart. 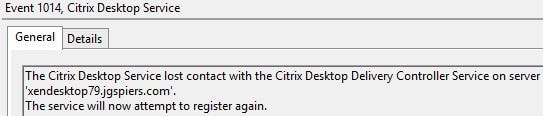 If for some reason it tries to register with a non-elected controller the connection will be refused.
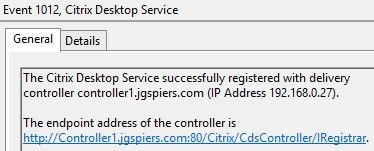
If for some reason it tries to register with a non-elected controller the connection will be refused. 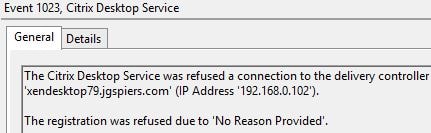 The VDA will then end up registering with the elected controller.
The VDA will then end up registering with the elected controller.
Note: By default, VDA registration to a Delivery Controller occurs over TCP port 80. If you have changed the default port of the Citrix Broker Service on each Delivery Controller, you must also change the Citrix High Availability Service port to the same. If you do not, VDAs will not be able to register with the Citrix High Availability Service. To do this you can run C:\Program Files\Citrix\Broker\Service\HighAvailabilityService.exe –VdaPort portnumber on your Delivery Controller(s).
 StoreFront will temporatily remove all non-elected controllers from the list of active services so they are not queried during resource enumeration or brokering.
StoreFront will temporatily remove all non-elected controllers from the list of active services so they are not queried during resource enumeration or brokering. 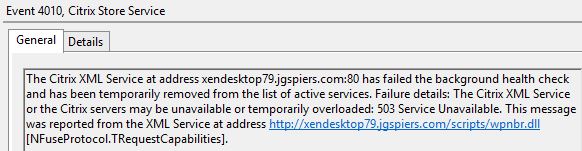 When users log on to StoreFront, the available resources are listed as normal. Communication for resource enumeration etc. between StoreFront and the Citrix High Availability Service is done via Controller1. You should now be able to launch resources as normal.
When users log on to StoreFront, the available resources are listed as normal. Communication for resource enumeration etc. between StoreFront and the Citrix High Availability Service is done via Controller1. You should now be able to launch resources as normal.  Note: Citrix Director will not receive any information from the Citrix Monitor Service during a database outage.
Note: Citrix Director will not receive any information from the Citrix Monitor Service during a database outage.
As the database is offline the Citrix Broker Service will monitor the connection to the Site database. Once the Site database is back online the Citrix Broker Service informs the Citrix High Availability Service that is will take over operations again.
 The Citrix Broker Service confirms normal brokering activity will resume.
The Citrix Broker Service confirms normal brokering activity will resume. 
Known issues/Improvements
- Users with connections to desktops might encounter problems reconnecting during an outage when LHC is used. If this happens, restart the Citrix High Availability Service.
- Citrix XenApp and XenDesktop 7.14 can now support an outage of 10K VDAs per zone up to a maximum of 40K VDAs per single site. Previously, you were limited to 5K VDAs.
Note on Citrix Cloud:
If using the Citrix Virtual Apps and Desktops Service, your Cloud Connector uses the Local Host Cache feature in the event of an outage to Citrix Cloud.
VDAs treat the Cloud Connector as a broker, which proxies connections to the Cloud Broker, but in the event of an outage to Citrix Cloud, a local copy of the database (that is hosted in Citrix Cloud with this service) is kept on the Cloud Connector. This allows the Cloud Connector to perform Cloud Broker duties a connection to Citrix Cloud is re-established. For Local Host Cache to work, you must use StoreFront on-premises.
Upgrading the SQL Express DB
Citrix added the option to move to a newer version of SQL Express LocalDB, in case your organisation have concerns regarding end of support from Microsoft for SQL Server Express LocalDB 2014.
If you upgrade your Delivery Controllers to version 1912 or 2003, upgrading the SQL Server Express LocalDB is optional. LHC works regardless with no loss of functionality.
However, if you upgrade your Delivery Controllers beyond version 2003, the minimum supported SQL Express version is SQL Server Express 2017 LocalDB CU 16. If you originally installed a Delivery Controller earlier than version 1912, and have not replaced SQL Server Express LocalDB with a newer version since the initial install, you must replace that database software after upgrading beyond 2003, otherwise LHC will not work. This does not affect fresh installs of 1912 or newer, as SQL Server Express version 2017 is installed by default.
To do this, obtain the Virtual Apps and Desktops media for the version you’ve upgraded to. The media contains a copy of Microsoft SQL Server LocalDB 2017 CU 16.
- Complete the upgrade of Virtual Apps and Desktops on all your Delivery Controllers.
- On the Delivery Controllers, download PsExec.
- Stop the Citrix High Availability Service.
- Run psexec -i -u “NT AUTHORITY\NETWORK SERVICE” cmd
- Run cd “C:\Program Files\Microsoft SQL Server\120\Tools\Binn”
- Stop and delete CitrixHA (LocalDB).
- SqlLocalDB stop CitrixHA
- SqlLocalDB delete CitrixHA
- Remove the related files in C:\Windows\ServiceProfiles\NetworkService
- HADatabaseName.*
- HADatabaseName_log.*
- HAImportDatabaseName.*
- HAImportDatabaseName_log.*
- Note: Your deployment might not have HAImportDatabaseName.* and HAImportDatabaseName_log.*
- Uninstall SQL Server Express LocalDB 2014 using add/remove programs.
- Install SQL Server Express LocalDB 2017.
- From the Virtual Apps and Desktops media, browse to Support -> SQLLocalDB and double-click sqllocaldb.msi. A restart might be required. The new SQLLocalDB resides under C:\Program Files\Microsoft SQL Server\140\Tools\Binn
- Start the Citrix High Availability Service.
- Ensure the Local Host Cache database was created on each Delivery Controller. This confirms the High Availability Service (secondary broker) can take over if required:
- From each Controller, browse to C:\Windows\ServiceProfiles\NetworkService and verify HaDatabaseName.mdf and HaDatabaseName_log.ldf have een created.
Pingback: Delivery Controller 7.12 and Licensing – Carl Stalhood
Shiva ch
December 7, 2016Hey George,
You have mentioned that LHC doesn’t support Pooled connections but citrix documentation says accessing pooled resources (shared desktops) is supported.
https://docs.citrix.com/en-us/xenapp-and-xendesktop/7-12/whats-new.html
Shiva ch
December 7, 2016nvm, I think it only supports Hosted Shared desktops not VDIs.
George Spiers
December 7, 2016Correct, pooled VDI desktops are not supported. Server based VDA and static VDI is supported with LHC.
shiva ch
December 19, 2016Do you know if it’s going to support pooled VDIs in coming releases?
George Spiers
December 19, 2016That I don’t know for now however I would bet that there will be support in future releases as pooled VDI desktops play such a large part in many organisations.
Jeyaganesan
March 5, 2019Yes I agree. LHC won’t support for pooled VDI desktops(created buy PVS and MCS). Any technical reason background for this? We have non persistent XenApp in our environment created in PVS. will it support the LHC if DB down?
George Spiers
March 7, 2019Pooled VDI desktops are not supported, but if you are using published apps and desktops provided by XenApp (Virtual Apps) you are covered by LHC.
Nikhil
December 9, 2016Does monitor Service still monitors during the SQL DB inaccessible. Once the SQL DB is accessible does monitoring service resumes writing to MDB?
George Spiers
December 9, 2016No and yes the monitor service resumes once the Citrix Broker Service detects the SQL database is back online.
Pingback: Delivery Controller 7.13 and Licensing – Carl Stalhood
Vipin Tyagi
March 29, 2017I have some concerns.
Principle broker service, CCS, Secondary Broker service, Local BD is on all DDC. LHC also will be on all DDCs? How can we check LHC (like XA 6.5, there was a file).
In Normal cases, Sessions will be load balanced among multiple DDCs; CSS will query Principle Broker Service to get changes in every 2 min and Will re-create LHC DB if got positive answer ( changes found). Question is :Principle Broker Service on each DDC will contact to Site DB to get changes (Changes might have been done on other domain controller)? How frequent? Won’t it increase Load on DB? How this load is handled?
Secondary Broker Service will also get a list of other Secondary Broker service in Zone (Secondary broker service on other DDC). There will be an election process to elect one working Secondary broker service among these all. In case of failure, Sessions will be served by only this main secondary service hence no session load balancing. All VDAs will be re-registered. Question is : Will it not impact performance of service as all VDA needs to be registered with one Service at the same time. How this is handled?
In case of connection failure only with 1 DDC, LHC will be triggered? How other DDCs will know? In case of connection failure with all DDCs in Zone, How all DDCs will verify it?
Thanks in Advance
Vipin Tyagi
George Spiers
March 29, 2017Yes LHC is on all DDCs, so each DDC has LocalDB installed, all the configuration files are stores in %ProgramFiles%\Microsoft SQL Server\120\LocalDB\. The LHC database is located in C:\Windows\ServiceProfiles\NetworkService\HaDatabaseName.mdf.
Yes each Principal Broker Service speaks directly with SQL, changes made on another Domain Controller wouldn’t be stored in SQL? Changes made to the Citrix Site database are detected by the Principal Broker Service. Such changes are made via Studio/PowerShell.
Yes VDA re-registration will impact performance, that’s how the current architecture works. Citrix tested this current first release of LHC with up to 5K VDAs. It takes ALL DDCs to lose contact with the database for LHC to be triggered, one DDC won’t trigger LHC.
Vipin Tyagi
March 30, 2017Thanks for your reply,
changes made on another Domain Controller wouldn’t be stored in SQL: sorry for mistyping, I meant for DDCs. So Principle Broker service will contact to SQL to detect changes made in site. Frequency for this would be 2 min as well?
What mechanism is being used to detect that its One DDC failure or ALL DDC failure?
Secondary broker service will be elected after failure or before failure?
George Spiers
March 30, 2017Hi Vipin.
If a change is detected on the Principal Broker, the Citrix CSS is used to copy the configuration to the Citrix High Availability Service. A new LHC is generated as you mentioned previously containing all the previous and new configurations. That data is then imported in to the LocalDB database. If no changes have happened, no config is copied. The Citrix Broker Service is the Principal Broker, so this service checks SQL every 2 minutes for new configuration.
CSS continually provides information to each DDC about all controllers in a zone or site, the brokers communicate amongst eachother so I’d assume this way detection of one or all DDCs could be made. If there is a failure, the secondary broker is elected after failure. This can be around 1-2 minutes.
Pingback: Delivery Controller 7.14 and Licensing – Carl Stalhood
Pingback: Delivery Controller 7.15 LTSR and Licensing – Carl Stalhood
Pingback: Local Host Cache Events for XenApp/XenDesktop – theaaronstrong
Dipo
October 18, 2017Very Very good detailed Post. Weldone George , Great information !
Dan
February 3, 2018I have a question regarding local host cache that I can’t seem to find the answer to. Great article by the way–it contains details not found in the Citrix documentation concerning local host cache. I understand that the election of, as you put it, the “in-charge” controller that will be the lone broker for VDA registration and brokering duties during a database outage occurs while the database is still online. Here’s what I’m curious about… Let’s say there is an issue (maybe not all brokers use the same DNS servers for example) such that the database is actually online but the elected broker can’t contact it because it can’t resolve the name of the database server due to an issue with the DNS server the it is configured to use. But let’s say the other non-elected controllers can still contact the database. What happens in this case? Since this broker already knows it is the elected broker and it can’t contact the database, will the behavior that occurs be the same as if none of the brokers could contact the database? In other words, does this trigger all VDAs to re-register with the elected broker and do the other non-elected brokers start refusing connections? Conversely, what happens if one or more of the non-elected brokers can’t talk to the site database but the elected broker can? Do you know what happens in this case? Thanks!
George Spiers
February 3, 2018Hey – if a DDC loses SQL connectivity then it is normal behaviour for it to enter Local Host Cache mode. Since it is the only one that experiences the outage and we assume the DNS issue ALSO prevents the DDC contacting any of the remaining DDCs, it in my theory should elect itself. If it can still contact other DDCs then there really should be a review of the site setup. Any VDA that is registered to it will re-register with the High Availability Service. DDCs that continue to have a connection to SQL operate as normal, including the VDAs registered to those DDCs. In your scenario, since we have separate DNS servers and such we assume you have zones and portions of your farm are siloed. If not then you really should not have these points of failure in a farm. Anyway, when the DDC and SQL re-establish a connnection, the primary Broker Service should take back control and all VDAs will again register with this service.
My best advice would be to test the different scenarios yourself and always document the outcomes so you can be prepared for any situation.
Kumar
June 29, 2018Hello George,
Thanks for great article..!!! but I have one on going issue, can you please help me :-
> I have newly build citrix environment 7.15 LTSR CU2-XenApp, I have checked from power shell that connection leasing is disabled & LHC is enabled but my lhc is not working as expected. when connection to DB was lost no application enumeration happens.
> Infact I can’t find any files under “C:\Windows\ServiceProfiles\NetworkService” i.e. HaDatabaseName.mdf file folder is empty. Does this means that HA database (local-database) is not created?
> I can see two files in folder “C:\Program Files\Microsoft SQL Server\120\LocalDB\Binn” i.e. mssqlsystemresource.mdf & mssqlsystemresource.ldf .
> I can’t see any event ID 503, 3504,3502,505 but I see event id of 1201,3501 on any of my DDC. In my environment I have two DDC.
> I have tried restarting broker, configuration sync, HA service on DDC but not event ID of 503,504 recorded on DDC.
> I have also tried disabling & enabling LHC via PowerShell but no success.
Can you please provide your suggestion how can fix LHC issue in my environment, If you have seen this issue.
Thanks.
George Spiers
June 30, 2018Hi Kumar
You don’t see the HaDatabaseName.mdf file under C:\Windows\ServiceProfiles\NetworkService?
Do you see Microsoft SQL Server 2014 Express LocalDB listed in Add/Remove Programs on the DDC?
Kumar
July 2, 2018Hi George
> I can’t see HaDatabaseName.mdf file under C:\Windows\ServiceProfiles\NetworkService.
> I can see Microsoft SQL Server 2014 Express LocalDB listed in Add/Remove Programs on the DDC.
what can be other reasons according to you that LHC is not working ?
Thanks.
George Spiers
July 2, 2018Are your Citrix Broker Service and Citrix High Availability Service services running under Network Service?
Browse to the root of C:\ and search for “HaDatabaseName”, does it appear anywhere?
Pingback: Delivery Controller 7.17 and Licensing – Carl Stalhood
Pingback: Delivery Controller 7.16 and Licensing – Carl Stalhood
Pingback: Delivery Controller 7.18 and Licensing – Carl Stalhood
Kumar
July 2, 2018Yes, I checked Citrix Broker Service, Citrix High Availability & Citrix configuration Sync service are running under Network Service & all are up and in running state.
No, I can’t see any “HaDatabaseName” in root of “c:\”
Thanks
George Spiers
July 2, 2018Restart the High Availability Service, launch ProcMon and after a few moments sqlserver.exe should attempt to create HaDatabaseName.mdf. Filter on “Path contains HaDatabaseName”. Look for Access Denied type results.
Kumar
July 2, 2018Sure, I am checking and will get back with result as soon as possible.
Thanks George for your quick help/replies 🙂
Kumar
July 2, 2018I ran procmon and restarted HA service thrice also broker & configuration sync services and filtered output based on process name i.e. “sqlservr.exe”. All the operations named “read/write files” with results are showing as “SUCCESS” and are pointing to path “C:\Windows\WID\Binn\…”. Nowhere in the path tab is having location pointing to “C:\Windows\ServiceProfiles\NetworkService” or creating HADatabaseNmae.mdf file 🙁
Thanks.
George Spiers
July 3, 2018Don’t filter on sqlservr.exe, it is better to filter on “HADatabaseName” as part of the path. I suggest you run the steps again.
Kumar
July 3, 2018Tried again with filter on “HADatabaseName” as part of the path, Can’t find any entry after restarting HA service.
Can this issue be due to Antivirus on deliver controller, because I have AV on controller server and no exclusion has been applied in AV ?
George Spiers
July 3, 2018Yes possibly, but I was hoping something would be picked up in ProcMon. Try disabling AV temporarily.
Kumar
July 3, 2018Sure, I will try disabling AV & get back with results asap.
Thanks.
Kumar
July 3, 2018Disabling AV didn’t worked out.
George Spiers
July 3, 2018Have you installed SQL Server or SQL Express on your DDC that was NOT installed by XenDesktop i.e. you installed yourself? Where is the Site database stored, is it on a separate SQL server? Have you multiple DDCs all facing the same problem?
Kumar
July 26, 2018Hello George,
I found the root cause why LHC was not getting created is bcz “For Local Host Cache to work correctly, the PowerShell execution policy on each Controller must be set to RemoteSigned, Unrestricted, or Bypass” in my environment execution policy was in “allsigned” state that’s the only reason that LHC was not able to get imported from site DB to deliverycontroller. After setting execution policy to unrestricted then restarting config sync & HA service import of DB was successful 🙂
Thanks for your help.
George Spiers
July 26, 2018Good work! Thanks for letting me know.
Pingback: Delivery Controller 1808 and Licensing – Carl Stalhood
Anonymous
December 19, 2018Could you please tell me How many days the Local Host cache in XA/XD 7.15 will support in case of the Database corruption/down in the production environment.
George Spiers
December 20, 2018LocalDB will consume more resources the longer the outage lasts and the more launches that occur during the outage, so I imagine this would be the limiting factor before anything else.
Pingback: Delivery Controller 1811 and Licensing – Carl Stalhood
KS
April 8, 2019Hi
it may silly question, if site having 4 ddc.s, so which one will be the Principal broker
George Spiers
April 9, 2019Alphabetical order of the DDC names.
Kailas
April 9, 2019Thanks for reply
So if DDC1,DDC2,DDC3, Principal broker will be DDC1. if DDC1 failure the next election will be move among DDC2 and DDC3, the election will be DDC2 is that correct ?
George Spiers
April 9, 2019Yes, each DDC uses an FQDN list in alphabetical order to determine the elected broker.
Kailas
June 17, 2019Thanks George.
I have 3000 VD site with 3 DDC.
If DDC1 act as Principal broker, ddc1 is responsible for contacting the database to get any new update or changes, but the registrations will across the dcc are equal on normal mode, means DDC1 connected with 1000 VDA’s, ddc2 – 1000, ddc3 -1000. Is that correct?
In outage mode one – ddc2 will take the registration responsibility and will re-register all vda’s from ddc1 (1000 vda)/ddc3 (1000 vda) to DDC2 (3000).
George Spiers
June 17, 2019Yes that is correct.
Josh Lee
May 3, 2019Thanks for the great article. I refer to in frequently when I need a refresher. Just a quick question about DDC election. Does a new election happen every two minutes when the Broker Service does it’s check-in? That’s about what I’m seeing in my environment and have never been sure if that’s normal behavior or if I have some soft of misconfig.
George Spiers
May 4, 2019Nope that’s what I see in my environment aswell.
Jason Rogers
May 16, 2019Can I get a bit of clarity? Does HaDatabaseName.mdf exist on just the DDC’s and not the VDA’s?
George Spiers
May 16, 2019Yes just on DDCs.
robert jaudon
September 23, 2019George,
Thank you for the post and your blog rocks!!
Question about LHC and seeing multiple (hundreds) of 3504 events in the application logs. Is it normal to see hundreds of the errors in the logs? The 3504 message is “The Citrix High Availability server has become the elected instance amongst its peers”
When I run a Scout capture and look in the eventlogs I see hundreds of 3504 information events. Is this an indication of a database connectivity issue.
George Spiers
September 29, 2019Thanks. I don’t think it is a problem. You would get other events logged for when database connectivity is lost. I’ve seen event 3504 many times also.
paul
November 24, 2019Excellent back and forth discussion. What I have not really read in these threads is the impact all of this backend system work is having on end-user sessions. I am all familiar with the workings of IMA and the LHC in the XA65 and earlier space where users can operate really without issue if the Datastore was unavailable (outside of the obvious of not being able to perform any updates in the console (disable apps, add apps, etc.). What I am not able to find in most posts about LHC in the XA7.15 and above space is the end user impact/experience as all the VDA re-registration is happening.
What am I expected to see in Studio with respect to sessions?
I have seen where the unavailability of the Site Database has caused issues with users not seeing any of their XA7.15 published apps in Storefront. I would not have expected that to be the case (as it never was with XA65 and the Datastore being unavailable), and all that I have read for the LHC changes being more robust in XA7.15, there is a significant amount of activity happening in the background (than ever before) when the Site DB is unavailable.
Can someone speak to more detail about the User’s experience?
Do they get messages?
Do they see delays?
I am the Citrix Engineer for a Healthcare System and knowing what happens in the background is as equally important as what the User experience.
Thank you,
/paul
George Spiers
December 3, 2019Paul
Users with existing sessions should not experience any issues at all. The VDA they are on will re-register with the Delivery Controller in the background which has been elected primary.
In some situations if a user was to log on during the re-registration period they may see a slight delay in the launching of their applications, but there should be no hard stop.
I always recommend during deployments to test LHC to make sure it is functional and working as expected, and give each of your Delivery Controllers around 3GB RAM more in the event they have to act as a primary during outage.
Pingback: Delivery Controller 1912 LTSR and Licensing – Carl Stalhood
John Perkins
January 4, 2020Hello George, I have a question around LHC and DNS. Let’s say DNS is having issues and the SQL cluster is down, both from a network related issue. We have 3 DDCs in the same Network segment and LHC is not working, causing a full outage with no VM publications, etc. We are using MCS, full clones, persistent. What is the expected behavior since DNS is impacted? Should it work in this scenario?
George Spiers
February 17, 2020VDAs may not re-register with the new elected primary Controller if DNS is not resolving, unless they have cached entries. LHC is for SQL outages but when you include other outages the outcome may vary. I’d expect issues with AD components, such as domain controller authentication issues, Group Policy processing failures and so on.
JB
April 24, 2020We’re running XA 7.15 LTSR CU5 with 2016 Server VDAs. This week we encountered a power issue in our primary data center that hosts our SQL cluster. We were seeing a lot of inconsistency with LHC mode. It seemed like sometimes users would login to SF, they see no app/desktop icons listed. Sometimes refreshing the page would cause them to show up. Even if the icons did show up and the user attempted to launch a local resource (as I know from the docs that you cannot launch a resource located in another zone with LHC active), sometimes the resource would fail to launch while other times it would succeed. We have three zones with two delivery controllers in each zone. We have a StoreFront server at each of our locations pointed at both delivery controllers in each zone. From the logs we saw the following:
4/20 2:24 PM connection to database was lost events 1201/3501 on delivery controllers
4/20 2:25 PM HA becomes active event 3502 on delivery controllers
4/20 ~2:34 PM VDAs register with secondary broker event 1012 on VDAs
The Citrix HA event 1201 on delivery controllers continued to 2:48 PM on 4/20
I confirmed login was successful at 3:23 PM and connections appeared to stabilize throughout the evening of 4/20
4/21 starting 5:31 AM alternating messages 1201 connection to db lost and 1200 connection restored from ha service through 9:54 AM — during this time connections were intermittent, sometimes no icons were presented, other times icons were presented by launching an app would fail even for a VDA within the same zone, no real pattern to it but some users did manage to get logged on
4/21 9:55 AM Access to db was restored with events 3500/3503 reporting normal brokering operations resumed on the delivery controllers
During the time we had intermittent connection issues, StoreFront reported various errors:
The Citrix servers reported an unspecified error from the XML Service at address
All the Citrix XML Services configured for farm failed to respond to this XML Service transaction.
Failed to launch the resource ‘Desktop $S3-6’ using the Citrix XML Service at address
I’m not sure if the alternating 1200/1201 errors are meaningful in the sense that the elected delivery controller which was in HA mode was thinking the database was live but clearly it wasn’t? I would only expect to see those messages during the initial loss of connectivity to the SQL db and then again during restoration of connectivity to the SQL db. From what I can tell, the VDAs did register with the elected secondary broker fairly quickly (with 10 minutes). I thought about maybe the number of connections overwhelmed the broker but from what I read Citrix says its good for 10k sessions. We only have a couple hundred users and when the issue started back up the morning of 4/21 there was probably a steady stream of connection attempts but not so many that it should overwhelm a broker running in HA mode. I’m just puzzled as to what was going on. Any insights would be appreciated.
George Spiers
September 9, 2020I guess the key piece is those 1200 and 1201 events and why they only started to occur 12+ hours after the initial outage. I wonder had the SQL team been doing anything at that time, or was there intermittent access back to the primary data center from 5am.
Pingback: Citrix VAD local host cache vs connection leasing - Hybrid Cloud Blog
Pingback: Delivery Controller 1912 LTSR CU1 and Licensing – Carl Stalhood
Anonymous
May 20, 2020Hello George, I have a question suppose if my sql server down for 3 0r 4 months what will happen, will it it still use the LocalDB(LHC)
Hector
September 17, 2020Hello:
When I tired to access the path to \tools\binn as network service I get access denied. I check whoami and it shows network service. If i check the security in the folder, network service is not there but system is. As system i can get to the binn folder. If I check the service profile\network service folder the DB’s are there. Why would this happen. Thanks
Gunther
October 15, 2020Hi George,
Have you seen any issues with the High Availability Service with Virtual Apps 7.2009. With this version it is complaining that there are no valid licenses and it goes into Grace-period. Hours start counting down. Very strange. Everything else seems normal. License server is fine, Delivery Controllers are fine, Director shows every thing ok, sessions are being brokkered. I think there is a bug in the High Availability Service in 7.2009. It works though, as I have broken connection to the databases and it kicks in just fine. Allready reported to Citrix support but I thought that you might have picked something up?
Best regards,
Gunther
PPS
December 3, 2020Hi George,
During LHC I see storefront reporting the event 4010, that is 503 service Unavailable.
But even after 25 minutes, no secondary controller reported healthy by storefront, and application enumeration is not happening.
I can see on the controller LHC is getting activated and on the VDA I can see they are getting registered correctly.
But the XML communication between controller and storefront is not happening at all
Any idea how long it will take.
We have 4 controllers and 2 zones. 2 controllers in each zone.
Pingback: Delivery Controller 2203 LTSR and Licensing – Carl Stalhood